
JPA N+1 이 무엇인지 그리고 어떻게 최적화하는지 알아보도록 하자!
✔️ JPA N+1 문제란?
다대일 관계 Member와 Team를 정의해봅시다.
@Entity
@NoArgsConstructor
@AllArgsConstructor
@Builder
@Getter
@Setter
public class Member {
@Id
private Long memberId;
private String memberName;
@ManyToOne
private Team team;
}@Entity
@NoArgsConstructor
@AllArgsConstructor
@Builder
@Getter
@Setter
public class Team {
@Id
private Long teamId;
private String teamName;
@OneToMany(mappedBy = "team")
private List<Member> members;
}이제 Team 를 출력하면서 해당되는 members를 같이 출력해봅니다.
@DataJpaTest
public class JpaTest {
@Autowired
MemberRepository memberRepository;
@Autowired
TeamRepository teamRepository;
@Autowired
TestEntityManager em;
Logger logger = LoggerFactory.getLogger("JpaTest");
@Test
void findAllTeam_print_only_teamName() {
List<Team> teams = teamRepository.findAll();
List<Team> collect = teams.stream().peek(t -> logger.info("team Name {} ", t.getTeamName())).collect(Collectors.toList());
Assertions.assertThat(teams.size()).isEqualTo(2);
}
@Test
void findAllTeam_print_members() {
List<Team> teams = teamRepository.findAll();
List<Team> collect = teams.stream()
.peek(t -> logger.info("members Id {} ", t.getMembers()
.stream()
.map(Member::getMemberName)
.collect(Collectors.toList())))
.collect(Collectors.toList());
Assertions.assertThat(teams.size()).isEqualTo(2);
}
@BeforeEach
void init() {
Team team1 = Team.builder()
.teamName("Team1")
.build();
Team team2 = Team.builder()
.teamName("Team2")
.build();
teamRepository.save(team1);
teamRepository.save(team2);
LongStream.rangeClosed(1, 2).forEach(i -> {
memberRepository.save(Member.builder()
.memberName(String.format("memberName%s", i))
.team(team1)
.build());
});
LongStream.rangeClosed(3, 5).forEach(i -> {
memberRepository.save(Member.builder()
.memberName(String.format("memberName%s", i))
.team(team2)
.build());
});
em.flush();
em.clear();
logger.info("-----------저장 완료 -------------");
}
}


team 만 출력해야 한다면 team table에 해당하는 쿼리만 나가지만 멤버 변수인 members까지 출력하기 위해서는 member 테이블을 조회하는 쿼리가 더 나가야한다. 위의 예제에서는 `select * from member where teamId = 1` 과 `select * from member where teamId = 2` 가 더 나갔다.
즉 우리는 team 하나를 조회하고자 1개의 쿼리만 기대했지만 연관관계에 있는 member 때문에 N개의 쿼리가 더 나갔다. 이를 JPA N+1 문제라고 한다.
최대한 적은 쿼리를 보내기 위해 어떻게 최적화를 할 수 있을까?
💡 해결 방법 1. Join Fetch
@Query("select t from Team t join fetch t.members")
List<Team> findTeamFetch();@Test
void findAllTeam_print_members_using_fetch_join() {
List<Team> teams = teamRepository.findTeamFetch();
List<Team> collect = teams.stream()
.peek(t -> logger.info("members Id {} ", t.getMembers()
.stream()
.map(Member::getMemberId)
.collect(Collectors.toList())))
.collect(Collectors.toList());
Assertions.assertThat(teams.size()).isEqualTo(2);
}
join 쿼리를 통해 team의 멤버 변수 member까지 같이 가져온다. 그럼 하나의 쿼리를 모두 해결이 가능하다.
💡 해결 방법 2. EntityGraph
@EntityGraph(attributePaths = {"members"})
@Query("select t from Team t join fetch t.members")
List<Team> findTeamEntityGraph();테스트 코드와 결과 화면은 동일하므로 생략한다. join fetch 와 똑같이 join 쿼리가 날라가서 하나의 쿼리로 해결이 된다.
💡 해결 방법 3. BatchSize
@Entity
@NoArgsConstructor
@AllArgsConstructor
@Builder
@Getter
@Setter
public class Team {
@Id
@GeneratedValue
private Long teamId;
private String teamName;
@OneToMany(mappedBy = "team")
@BatchSize(size = 100)
private List<Member> members;
}
하나의 쿼리로는 해결 못하였으나 원래의 findAll() 보다 쿼리가 적게 날라간다.
최적화를 하기 전에는 teamId 하나 당 하나씩 member table로 쿼리가 날라갔으나 이번엔 member table로 하나의 쿼리가 날라간다. `select * from member where teamId in (1, 2)` 이런 식으로 where-in 절을 통해 필요한 데이터를 한꺼번에 가져온다. BatchSize는 in 절에 몇 개까지 들어갈 수 있느냐를 정하는 파라미터다.
❗fetch join 주의할 점
1. (OneToMany) 절대로 Pagination 에 사용하지 않는다.
원래는 Limit 만큼 데이터를 가져와야 하지만 OneToMany에 fetch join 를 쓰면 실제 데이터보다 더 많은 레코드들이 가져와진다. 이 중에서 본래의 Limit 만큼이 얼만큼인지 연산을 해주어야 하는데 Hibernate는 이를 위해 Limit 와 상관 없이 일단 모든 레코드들을 메모리에 올려버린다.
2. (OneToMany) 중복된 결과가 생길 수 있다.
그래서 원래는 따로 distinct 처리를 해주어야 하지만 Hibernate 6.0 부터 distinct 처리를 해준다고 한다.
3. (OneToMany) 둘 이상의 컬렉션을 Fetch Join 할 수 없다. MultipleBagFetchException
java의 List 타입은 기본적으로 Hibernate의 Bag 타입으로 맵핑된다. 이때 Bag은 중복 요소를 허용하는 unordered 컬렉션이다. 여기서 문제가 발생한다.
둘 이상의 컬렉션 Bag를 Fetch Join 하는 경우 어느 행이 유효한 중복을 포함하고 있고 어느 행이 그렇지 않은지 판단할 수 없어 두 개 이상의 OneToMany Fetch Join 를 제한시킨다.
어느 행이 유효한 중복을 포함하고 있고 어느 행이 그렇지 않은지 판단할 수 없다는 말이 참 이해가 안됐는데 구글링해도 잘 안보여서 직접 생각해보았다.
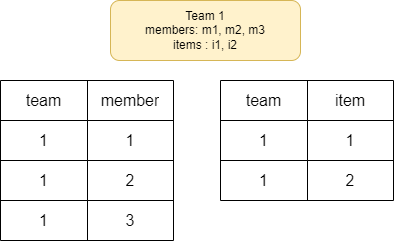
team1 이라는 객체 하나가 여러 개의 member, item를 가지고 있다. 그렇다면 데이터베이스에서는 위와 같을 것이다.
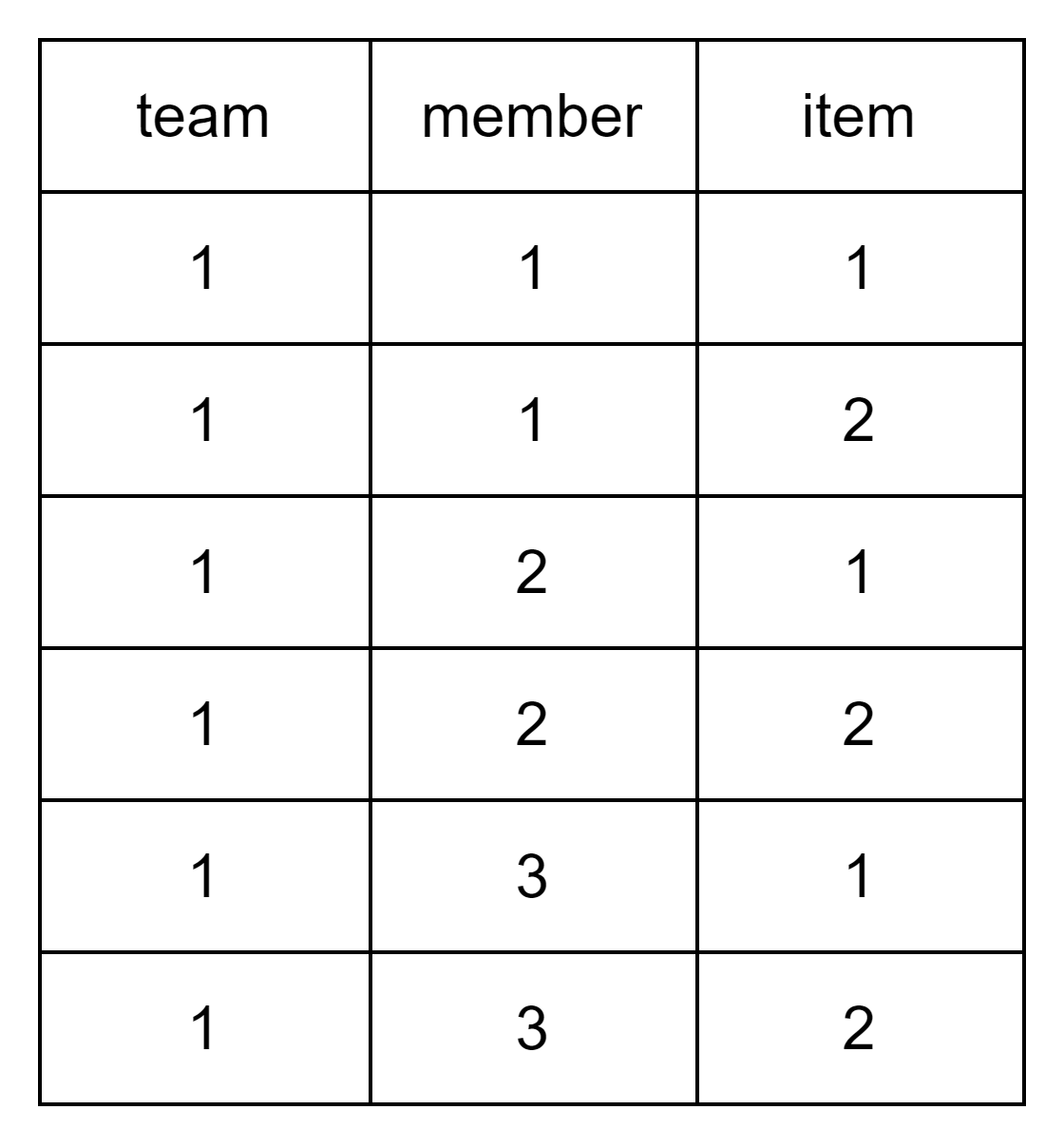
이 두 개의 테이블을 카르테시안 곱을 하면 다음과 같고 다음 쿼리의 결과물을 생각해보자.
select count(m) from Team t join fetch t.members join fetch t.items where teamId = 1
생각나는 쿼리 쓴거라 정확하진 않을 수 있습니다.
Bag이라는 컬렉션 자료형을 통해 우리는 members = [1, 1, 2, 2, 3, 3] 이라고 저장해뒀다. 그렇다면 멤버는 몇 개로 세야하는 것일까? 같은 MemberId에 대해 ItemId가 다르다면 중복으로 카운트해야할까 아닌걸까? 중복이 허용되는 자료형이기 때문에 중복이 포함돼서 일단 멤버 count 가 6이 된다. 이는 우리가 원하던 바가 아니다. 어찌보면 객체와 데이터베이스 row의 개념 차이에서 발생하는 오류이다.
이러한 일을 방지하기 위해 OneToMany에서의 FetchJoin 은 제한되는 것이다.
해결 방법이 있긴 하다.
1. List를 Set으로 변경하여 중복 허용을 애초에 하지 않는다.
2. OrderColumn 으로 우선순위를 준다.
✅ 결론
OneToMany : fetch join 은 문제가 많으니 batch size를 쓰도록 하자
ManyToOne : batch size를 쓰게되면 결국엔 여러 개의 쿼리가 나갈테니 fetch join 를 쓰도록 하자
개인적으로 [NHN 컨퍼런스 JPA의 사실과 오해] 내용 알차서 좋았다 👏
참고
https://ttl-blog.tistory.com/1135#%F0%9F%93%95%20fetch%20join%20%EC%82%AC%EC%9A%A9-1
[JPA] N+1 문제가 발생하는 여러 상황과 해결방법
🧐 N + 1 문제 N + 1 문제는 연관관계가 설정된 엔티티 사이에서 한 엔티티를 조회하였을 때, 조회된 엔티티의 개수(N 개)만큼 연관된 엔티티를 조회하기 위해 추가적인 쿼리가 발생하는 문제를 의
ttl-blog.tistory.com
https://kjhoon0330.tistory.com/85#comment14190220
[Spring & JPA] N + 1 문제에 대하여.
0. 들어가며 🏃🏻♂️ 이번 글에서는 JPA를 사용할 때 중요한 개념인 N + 1 문제에 대해 알아보려합니다. N + 1 문제는 JPA를 처음 공부할 때부터 중요하다고 들었고, 이에 대한 해결법 역시 대략
kjhoon0330.tistory.com
'☘️Spring' 카테고리의 다른 글
| [Spring] 스프링 시큐리티 인증/인가 및 에러 삽질 (3) | 2024.02.04 |
|---|---|
| [Spring] 스프링 시큐리티 기초 정리 (1) | 2024.01.21 |
| [Spring] MockMvcTest vs End-to-End Tests (1) | 2023.10.26 |
| [Spring] web mvc 코드로 이해하기 (0) | 2023.09.02 |
| [Spring] 의존관계 자동/수동 주입 (0) | 2023.07.09 |
JPA N+1 이 무엇인지 그리고 어떻게 최적화하는지 알아보도록 하자!
✔️ JPA N+1 문제란?
다대일 관계 Member와 Team를 정의해봅시다.
@Entity
@NoArgsConstructor
@AllArgsConstructor
@Builder
@Getter
@Setter
public class Member {
@Id
private Long memberId;
private String memberName;
@ManyToOne
private Team team;
}@Entity
@NoArgsConstructor
@AllArgsConstructor
@Builder
@Getter
@Setter
public class Team {
@Id
private Long teamId;
private String teamName;
@OneToMany(mappedBy = "team")
private List<Member> members;
}이제 Team 를 출력하면서 해당되는 members를 같이 출력해봅니다.
@DataJpaTest
public class JpaTest {
@Autowired
MemberRepository memberRepository;
@Autowired
TeamRepository teamRepository;
@Autowired
TestEntityManager em;
Logger logger = LoggerFactory.getLogger("JpaTest");
@Test
void findAllTeam_print_only_teamName() {
List<Team> teams = teamRepository.findAll();
List<Team> collect = teams.stream().peek(t -> logger.info("team Name {} ", t.getTeamName())).collect(Collectors.toList());
Assertions.assertThat(teams.size()).isEqualTo(2);
}
@Test
void findAllTeam_print_members() {
List<Team> teams = teamRepository.findAll();
List<Team> collect = teams.stream()
.peek(t -> logger.info("members Id {} ", t.getMembers()
.stream()
.map(Member::getMemberName)
.collect(Collectors.toList())))
.collect(Collectors.toList());
Assertions.assertThat(teams.size()).isEqualTo(2);
}
@BeforeEach
void init() {
Team team1 = Team.builder()
.teamName("Team1")
.build();
Team team2 = Team.builder()
.teamName("Team2")
.build();
teamRepository.save(team1);
teamRepository.save(team2);
LongStream.rangeClosed(1, 2).forEach(i -> {
memberRepository.save(Member.builder()
.memberName(String.format("memberName%s", i))
.team(team1)
.build());
});
LongStream.rangeClosed(3, 5).forEach(i -> {
memberRepository.save(Member.builder()
.memberName(String.format("memberName%s", i))
.team(team2)
.build());
});
em.flush();
em.clear();
logger.info("-----------저장 완료 -------------");
}
}
team 만 출력해야 한다면 team table에 해당하는 쿼리만 나가지만 멤버 변수인 members까지 출력하기 위해서는 member 테이블을 조회하는 쿼리가 더 나가야한다. 위의 예제에서는 select * from member where teamId = 1 과 select * from member where teamId = 2 가 더 나갔다.
즉 우리는 team 하나를 조회하고자 1개의 쿼리만 기대했지만 연관관계에 있는 member 때문에 N개의 쿼리가 더 나갔다. 이를 JPA N+1 문제라고 한다.
최대한 적은 쿼리를 보내기 위해 어떻게 최적화를 할 수 있을까?
💡 해결 방법 1. Join Fetch
@Query("select t from Team t join fetch t.members")
List<Team> findTeamFetch();@Test
void findAllTeam_print_members_using_fetch_join() {
List<Team> teams = teamRepository.findTeamFetch();
List<Team> collect = teams.stream()
.peek(t -> logger.info("members Id {} ", t.getMembers()
.stream()
.map(Member::getMemberId)
.collect(Collectors.toList())))
.collect(Collectors.toList());
Assertions.assertThat(teams.size()).isEqualTo(2);
}join 쿼리를 통해 team의 멤버 변수 member까지 같이 가져온다. 그럼 하나의 쿼리를 모두 해결이 가능하다.
💡 해결 방법 2. EntityGraph
@EntityGraph(attributePaths = {"members"})
@Query("select t from Team t join fetch t.members")
List<Team> findTeamEntityGraph();테스트 코드와 결과 화면은 동일하므로 생략한다. join fetch 와 똑같이 join 쿼리가 날라가서 하나의 쿼리로 해결이 된다.
💡 해결 방법 3. BatchSize
@Entity
@NoArgsConstructor
@AllArgsConstructor
@Builder
@Getter
@Setter
public class Team {
@Id
@GeneratedValue
private Long teamId;
private String teamName;
@OneToMany(mappedBy = "team")
@BatchSize(size = 100)
private List<Member> members;
}하나의 쿼리로는 해결 못하였으나 원래의 findAll() 보다 쿼리가 적게 날라간다.
최적화를 하기 전에는 teamId 하나 당 하나씩 member table로 쿼리가 날라갔으나 이번엔 member table로 하나의 쿼리가 날라간다. select * from member where teamId in (1, 2) 이런 식으로 where-in 절을 통해 필요한 데이터를 한꺼번에 가져온다. BatchSize는 in 절에 몇 개까지 들어갈 수 있느냐를 정하는 파라미터다.
❗fetch join 주의할 점
1. (OneToMany) 절대로 Pagination 에 사용하지 않는다.
원래는 Limit 만큼 데이터를 가져와야 하지만 OneToMany에 fetch join 를 쓰면 실제 데이터보다 더 많은 레코드들이 가져와진다. 이 중에서 본래의 Limit 만큼이 얼만큼인지 연산을 해주어야 하는데 Hibernate는 이를 위해 Limit 와 상관 없이 일단 모든 레코드들을 메모리에 올려버린다.
2. (OneToMany) 중복된 결과가 생길 수 있다.
그래서 원래는 따로 distinct 처리를 해주어야 하지만 Hibernate 6.0 부터 distinct 처리를 해준다고 한다.
3. (OneToMany) 둘 이상의 컬렉션을 Fetch Join 할 수 없다. MultipleBagFetchException
java의 List 타입은 기본적으로 Hibernate의 Bag 타입으로 맵핑된다. 이때 Bag은 중복 요소를 허용하는 unordered 컬렉션이다. 여기서 문제가 발생한다.
둘 이상의 컬렉션 Bag를 Fetch Join 하는 경우 어느 행이 유효한 중복을 포함하고 있고 어느 행이 그렇지 않은지 판단할 수 없어 두 개 이상의 OneToMany Fetch Join 를 제한시킨다.
어느 행이 유효한 중복을 포함하고 있고 어느 행이 그렇지 않은지 판단할 수 없다는 말이 참 이해가 안됐는데 구글링해도 잘 안보여서 직접 생각해보았다.
team1 이라는 객체 하나가 여러 개의 member, item를 가지고 있다. 그렇다면 데이터베이스에서는 위와 같을 것이다.
이 두 개의 테이블을 카르테시안 곱을 하면 다음과 같고 다음 쿼리의 결과물을 생각해보자.
select count(m) from Team t join fetch t.members join fetch t.items where teamId = 1
생각나는 쿼리 쓴거라 정확하진 않을 수 있습니다.
Bag이라는 컬렉션 자료형을 통해 우리는 members = [1, 1, 2, 2, 3, 3] 이라고 저장해뒀다. 그렇다면 멤버는 몇 개로 세야하는 것일까? 같은 MemberId에 대해 ItemId가 다르다면 중복으로 카운트해야할까 아닌걸까? 중복이 허용되는 자료형이기 때문에 중복이 포함돼서 일단 멤버 count 가 6이 된다. 이는 우리가 원하던 바가 아니다. 어찌보면 객체와 데이터베이스 row의 개념 차이에서 발생하는 오류이다.
이러한 일을 방지하기 위해 OneToMany에서의 FetchJoin 은 제한되는 것이다.
해결 방법이 있긴 하다.
1. List를 Set으로 변경하여 중복 허용을 애초에 하지 않는다.
2. OrderColumn 으로 우선순위를 준다.
✅ 결론
OneToMany : fetch join 은 문제가 많으니 batch size를 쓰도록 하자
ManyToOne : batch size를 쓰게되면 결국엔 여러 개의 쿼리가 나갈테니 fetch join 를 쓰도록 하자
개인적으로 [NHN 컨퍼런스 JPA의 사실과 오해] 내용 알차서 좋았다 👏
참고
https://ttl-blog.tistory.com/1135#%F0%9F%93%95%20fetch%20join%20%EC%82%AC%EC%9A%A9-1
[JPA] N+1 문제가 발생하는 여러 상황과 해결방법
🧐 N + 1 문제 N + 1 문제는 연관관계가 설정된 엔티티 사이에서 한 엔티티를 조회하였을 때, 조회된 엔티티의 개수(N 개)만큼 연관된 엔티티를 조회하기 위해 추가적인 쿼리가 발생하는 문제를 의
ttl-blog.tistory.com
https://kjhoon0330.tistory.com/85#comment14190220
[Spring & JPA] N + 1 문제에 대하여.
0. 들어가며 🏃🏻♂️ 이번 글에서는 JPA를 사용할 때 중요한 개념인 N + 1 문제에 대해 알아보려합니다. N + 1 문제는 JPA를 처음 공부할 때부터 중요하다고 들었고, 이에 대한 해결법 역시 대략
kjhoon0330.tistory.com
'☘️Spring' 카테고리의 다른 글
| [Spring] 스프링 시큐리티 인증/인가 및 에러 삽질 (3) | 2024.02.04 |
|---|---|
| [Spring] 스프링 시큐리티 기초 정리 (1) | 2024.01.21 |
| [Spring] MockMvcTest vs End-to-End Tests (1) | 2023.10.26 |
| [Spring] web mvc 코드로 이해하기 (0) | 2023.09.02 |
| [Spring] 의존관계 자동/수동 주입 (0) | 2023.07.09 |